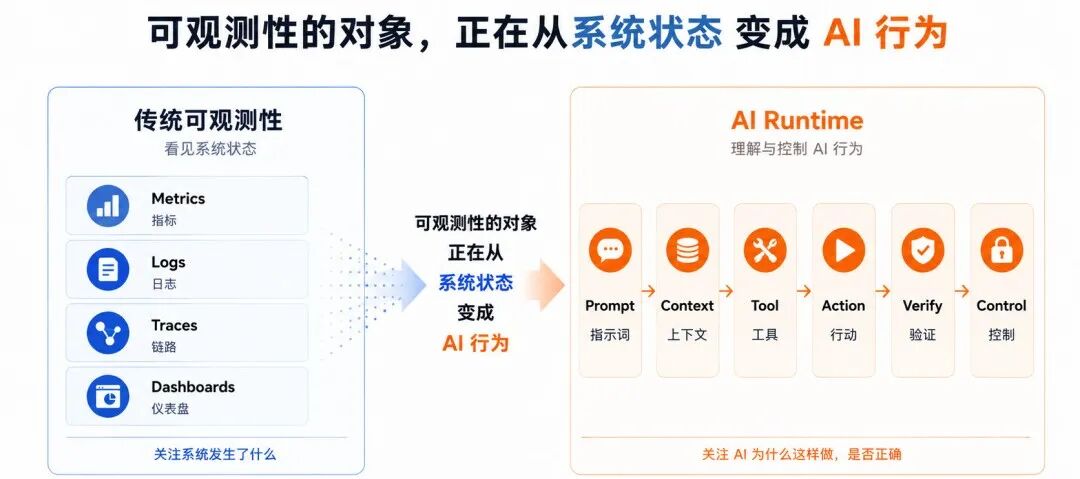
从“看系统状态”到“理解和控制 AI 行为”,可观测性的观察对象正在改变。
过去十多年,我基本都在 APM、可观测性、生产系统这些事情里打转。
从 JavaAgent、调用链、日志、指标、告警,到后来的全链路追踪、根因分析、AIOps,我经历过一轮又一轮“可观测性升级”。
但最近我越来越强烈地意识到一件事:
传统可观测性,开始越来越难理解 AI 系统。
不是因为监控没用了。
也不是因为 Trace、日志、指标突然不重要了。
而是因为:
过去我们观测的是:系统状态。
但 AI 进入生产以后,企业开始必须观测:AI 行为。
这两件事不是一回事。
接个大模型,不等于 AI 可观测性
现在很多可观测性产品都开始接 AI。
自然语言查指标。
自动总结告警。
帮工程师解释日志。
问一句“最近哪个服务有问题”,系统给你返回一段分析。
这些能力有没有价值?当然有。
它能降低查询门槛,也能减少很多一线排障成本。
但我想说的是:
这还不是 AI 时代真正的可观测性。
它更像是:
旧可观测性,加了一个 AI 交互入口。
原来人查指标,现在 AI 帮人查。
原来人看日志,现在 AI 帮人总结。
原来人看 Trace,现在 AI 帮人解释一遍。
这一步当然有用。
但它没有改变根本问题。
因为它观察的对象,仍然是传统系统:
-
CPU 有没有飙高;
-
接口有没有变慢;
-
错误率有没有上升;
-
调用链有没有断;
-
哪个服务异常;
-
哪次发布以后指标变差。
这些问题依然重要。
但 AI 进入生产以后,企业真正开始关心的是:
AI 为什么这样做?
这个问题,传统可观测性其实很难回答。
因为这背后已经不是“多采几条日志”的问题。
而是传统可观测性的底层假设,开始被 AI Runtime 改写了。
今天很多所谓 AI 可观测性,本质上还是:
旧监控平台,加一个 LLM 助手。
它解决的是:人怎么更快看数据。
但 AI Runtime 真正的问题是:
企业怎么理解和控制 AI 自己的行为。
过去十年,我们看的是“系统发生了什么”

传统 APM 和可观测性解决的问题,其实很清楚。
系统慢了,慢在哪里。服务挂了,挂在哪里。接口报错,错误从哪来。一次发布之后,哪个指标先变坏。
这些问题背后的逻辑是:
软件系统主要由代码、配置、调用关系和运行环境决定。
所以我们可以通过指标、日志、Trace、事件、拓扑,把系统状态拼出来。
这也是过去十多年可观测性行业最核心的价值。
它帮助企业回答:
发生了什么?
再进一步:
为什么发生?
但这里有一个很重要的隐含前提:
软件系统,大体是确定性的。
代码写好了,逻辑基本就固定了。
所以传统可观测性的核心,
是:还原系统状态。
但 AI Runtime 不一样。
AI 的行为路径,不再由代码提前写死。
它会受到 Prompt、上下文、Memory、RAG、权限和工具反馈共同影响。
同样的问题,今天和昨天可能会形成不同决策。
这意味着:
企业第一次开始面对一种新的生产系统:行为不稳定的生产系统。
这才是传统可观测性越来越看不懂 AI 的根本原因。
它擅长解释:确定性系统的状态异常。
但 AI Runtime 的核心问题是:
概率性行为系统的行动原因。
系统健康,不等于行为正确

AI 进入生产以后,企业不只是要知道:接口有没有报错;Trace 有没有断;延迟有没有升高。
企业还开始关心:
-
AI 为什么选择这个工具?
-
为什么引用这份知识?
-
为什么跳过了人工确认?
-
为什么认为这个动作可以自动执行?
-
为什么昨天没这么做,今天突然这么做了?
这些问题,已经不是传统的“系统状态问题”。
它们是:AI 行为问题。
过去运维看的是:系统有没有正常运行。
未来企业还必须看:AI 有没有正确行动。
系统健康,不等于行为正确。
过去的故障,更多是系统异常。
未来的故障,很可能是:
AI 在“系统看起来正常”的情况下做错了事。
一个工具返回 200,不代表它应该被调用。
一次自动修复执行成功,也不代表这个动作应该被允许。
真正危险的,不是 AI 说错,而是 AI 做错
很多人讨论 AI 风险,还停留在“幻觉”。
也就是:AI 胡说、答错、编造事实。
这当然是问题。
但在企业生产系统里,
更大的风险往往不是“说错”。
而是:做错。
因为 AI 正在获得执行权。
它可以调工具。可以写代码。可以执行 SQL。可以触发审批。可以改配置。可以重启服务。甚至可以建议和执行修复动作。
这时候问题的性质就变了。
以前 AI 答错了,最多是内容错误。
现在 AI 做错了,可能就是生产事故。
比如一个运维 Agent 自动执行修复动作。
系统可能完全健康。接口成功。脚本执行成功。服务指标恢复。
但问题是:
这个动作本来就不该被执行。
这才是 AI Runtime 最危险的地方。
如果企业回答不了:
-
AI 为什么这样判断?
-
它基于什么证据?
-
这个动作为什么被允许?
-
出了问题如何回滚?
那么即使 Dashboard 再漂亮,也只是:看到了动作发生。
并没有真正理解:动作为什么发生。
更没有能力控制它下一次会不会再发生。
这不是同一代问题。
帮助人类更快看数据,是人类运维时代的辅助工具。
理解 AI 自己的决策与行动,才是 AI 获得执行权之后的运行控制问题。
所以,AI 可观测性要看三条链

图:AI 可观测性不能只看调用链,还要看行为链、证据链和责任链。
我现在越来越觉得:AI 时代的可观测性,不能只看调用链。
调用链回答的是:
请求经过了哪些服务?
但 AI 生产化真正需要回答的是:
AI 为什么形成这个行为?
这就需要看三条链。
行为链,回答:AI 到底做了什么。
证据链,回答:AI 凭什么这么做。
责任链,回答:如果做错了,谁负责。
在金融、运营商、政企这些场景里,责任链尤其关键。
因为很多企业不是不想用 AI。
而是不敢把 AI 放进核心系统。
一旦出事,必须说得清楚。
说不清,就不敢授权。
判断 AI 可观测性,别只看有没有 AI 助手
以后企业看一个 AI 可观测性产品,我建议不要只问:
有没有大模型助手?
能不能自然语言查日志?
能不能自动生成告警摘要?
这些都只是第一层。
更重要的是四个问题。
第一,它能不能解释 AI 的行为路径?
第二,它能不能做错误归因?
第三,它能不能支持执行前验证?
第四,它能不能把事故变成下一次控制能力?
如果这些事情做不到,只是让 AI 帮你读日志、查指标、总结告警。
那它仍然停留在:
AI 化的可观测性。
而不是:
AI Runtime Control。
可观测性行业真正的变化:
从看见,到调查,到控制
我判断,中国可观测性行业正在进入一次真正的代际切换。
过去的价值中心是:能不能看见系统。
后来逐渐变成:能不能解释问题。
AI 进入生产以后,还会继续往前走:能不能控制行为。
未来几年,单纯“看系统”的可观测性价值会越来越被压缩。
因为采集正在标准化。监控正在平台化。
真正新的价值,会转移到:
AI 行为的解释、验证和运行控制。
过去 Observability 的核心是:人看数据。
未来企业真正需要的是:理解 AI 行为。
这也是为什么我认为:未来可观测性的价值中心,会从 Dashboard、Query、Trace,迁移到行为归因和运行控制。
企业根本不缺 Agent Demo。
真正缺的是:
谁敢让 Agent 进入生产。
而“谁敢让它做”,本质上就是可观测性行业的新问题。
因果 AI 要讲的,不是泛 AI 治理

我越来越觉得:
AI 获得执行权以后,企业真正缺的,不是更多 Agent。
而是一套新的运行控制体系。
我把它叫做:
AI Runtime Control。
它其实就是几个很朴素的问题:
-
AI 做了什么?
-
为什么这么做?
-
依据是什么?
-
动作有没有被验证?
-
出了问题能不能回滚?
-
下一次能不能避免?
如果用一个简单方法概括,就是:
Observe · Infer · Decide · Verify
先看见。再解释。再决定。最后验证。
没有验证的自动化,很容易变成事故放大器。
这一点,后面我会单独写。
最后
AI 进入生产以后,
企业最大的问题已经不是:AI 会不会做。
而是:
谁敢让它做。
这也是为什么传统可观测性会越来越看不懂 AI。
因为它擅长看系统状态。
但 AI 时代,企业还必须看运行时行为。
过去十年,可观测性治理的是:
代码运行系统。
未来十年,企业真正要治理的是:
AI 行为运行系统。
这不是一次简单的产品升级。
它更像一次新的生产系统革命。
#AIRuntimeControl #AI可观测性 #行为链 #生产系统 #AgentOps
推荐阅读