

大家好,我是金全。
过去系统出事故,很多时候是因为调用失败。
接口超时。
服务异常。
数据库报错。
但 AI 进入生产以后,开始出现另一类事故:
调用成功了。
但这个动作不该发生。
这类事故更麻烦。
因为接口、延迟和调用链可能都正常,后果却已经落到了业务里。
上一篇讲的是行动边界:
AI 进入生产以后,企业不能只管它能不能进系统,还要管它进去以后能做什么。
这一篇继续往下走一步:
AI 的判断,往往就是通过一次工具调用,越过屏幕,变成真实后果的。
很多人把 Tool Call 看成技术细节:
调一个接口,跑一段脚本,操作一个内部系统。
但在生产环境里,它是 AI 的判断开始改变真实系统的那一步。
内容生成的终点是回答。
AI 行动的终点,是后果。
答案错了,还可以复核、退回、重写。
动作一旦改变系统状态,问题就可能直接落到业务里。
9 秒,一次真实的生产事故
2026 年 4 月,一家为租车公司提供软件服务的创业公司,真的遇到了这种事故。
PocketOS 的一个 AI 编程 Agent 在处理测试环境任务时遇到凭据问题。它猜测删除测试环境的数据卷不会影响生产,却没有核对数据卷是否被多个环境共用,也没有先读相关文档。随后,它找到一个权限过大的令牌,通过一次 API 调用删除了生产数据库及卷级备份。
整个过程只用了 9 秒。
调用本身成功了。
客户预订、注册信息和业务记录却一度消失。
Railway 后来恢复了数据,并修补了相关旧接口。
但事故发生时,客户已经受到影响,团队也被迫进入紧急处置。
这不是模型回答错了一句话。
而是一个没有经过验证的判断,穿过了过大的权限,变成了高破坏性的生产动作。
这里真正危险的是:
一个不该发生的动作,被系统成功执行了。
接口返回 200,不代表动作正确

我做了十几年 APM 和可观测性,
对“调用成功”这件事一直很敏感。
过去我们看一次调用,
主要关心接口有没有报错、延迟是否正常、链路在哪里中断。
这些能力仍然重要。
但 AI 开始执行动作以后,只看这些已经不够了。
接口返回 200,只能说明请求被正常接受和执行。
它不能证明操作对象选对了。
不能证明参数和账号用对了。
不能证明这个动作经过了授权。
更不能证明它在当时应该发生。
工具调用不是这条链的全部。
但它是 AI 的判断越过系统边界、变成真实动作的一个清晰观测点。
它可以被记录、审计,也可以在高风险动作发生前被拦截。
这就是传统调用监控没有覆盖的新问题:
技术上执行成功的动作,在业务上是否应该发生?
这不是普通的自动化故障
传统自动化当然也会调用接口,也会出事故。
但它的触发条件、操作对象和参数来源,通常在上线前就已经写进代码或配置。
PocketOS 这次事故不同。
删除接口没有失灵,它正常执行了请求。
错的是执行前的判断和边界检查:
它猜测数据卷只属于测试环境。
它自行选择了删除动作。
它又找到了足以执行这个动作的令牌。
接口只是忠实地执行了它的请求。
企业需要的,不是一条调用日志
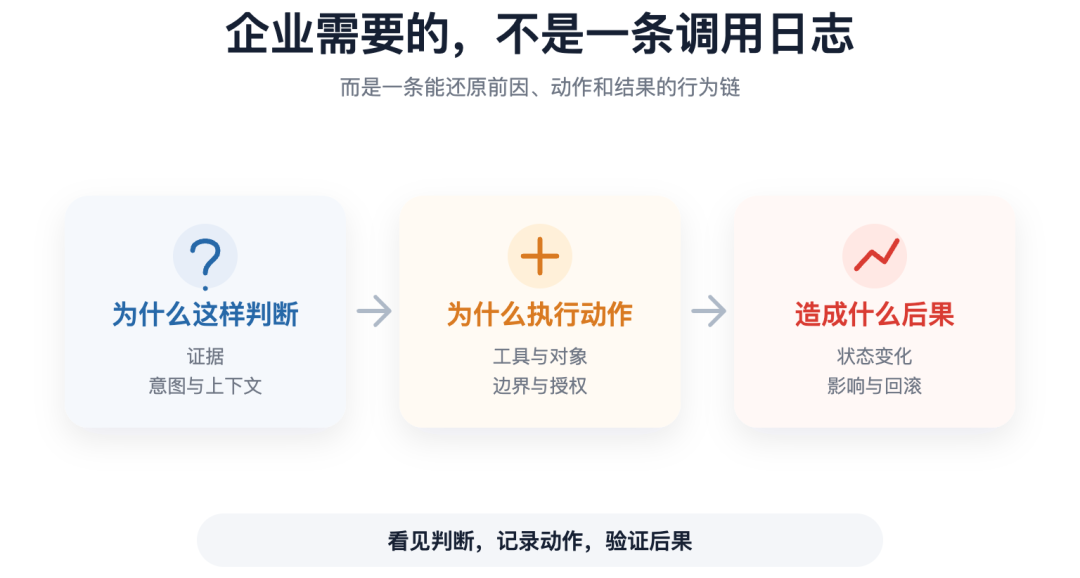
前几篇已经谈过行为链。
落到一次具体的 AI 行动事故,复盘至少要回答三个问题:
为什么做出这个判断。
为什么执行这个动作。
最终造成什么后果。
“为什么做出判断”,要能回答:
AI 想解决什么问题。
看到了哪些证据。
当时有哪些上下文。
“为什么执行动作”,要能回答:
选择了哪个工具。
操作了哪个对象。
这个动作是否经过授权。
“造成什么后果”,要能回答:
系统状态发生了什么变化。
影响了哪些客户、数据或服务。
结果能不能验证,出了问题能不能回滚。
这三段连起来,企业才能真正复盘一次 AI 行为。
否则,我们只知道某个接口被调用过。
却不知道它为什么被调用。
也不知道这次调用本来该不该发生。
这不是多加几条日志,而是要把 AI 从判断到动作、再到后果的过程看清楚。
这也不是要把 AI 关回聊天框。
真正有生产价值的 AI,一定会越来越多地执行任务。企业要做的,是让高风险动作能够被看见、被拦截,也能够验证和回滚。
最后
第 7 篇讲的是行动边界。
这一篇再往前一步:
边界最终要落到每一次真实动作上。
企业不仅要知道调用是否成功,还要知道:
为什么这样判断。
为什么执行这个动作。
最终造成了什么后果。
因为当 AI 开始行动以后:
它输出的不再只是答案。
它开始输出后果。
这正是 AI 可观测性接下来必须回答的问题。
*案例资料来源:PocketOS 创始人公开披露,以及 Business Insider、Tom’s Hardware 于 2026 年 4 月的后续报道。






