

大家好,我是金全。
过去一年,越来越多产品开始记录 Agent 经过了哪些步骤、调用了哪些工具、查了哪些数据。
但我越来越觉得:
看见 Agent 做了什么,不等于已经解释了这次行为为什么形成。
这也是今天讨论 AI 可观测性时,
最容易被忽略的区别。
先把讨论范围说清楚。
这篇讲的不是用 AI 分析日志、排查故障。
那是 AI for Observability,
也就是用 AI 改进传统可观测性。
这篇要讨论的是另一件事:
企业应该怎样观测 AI 应用和 Agent。
大家已经不满足于只看模型了,
开始看 Agent 做了什么,
以及哪一步出了问题。
现在,连运行在开发者电脑上的 Coding Agent,
也开始被纳入行为追踪范围。
一轮会话经过了哪些步骤,
调用了什么工具,
修改了哪些文件,
执行了哪些命令,
都开始被记录下来。
专业一点说,
AI 可观测性正在从模型调用监控,走向 Agent 运行过程的监测。
说到底,就是要把 Agent 的工作过程留下来。
Agent 的行为不是一次孤立调用,
而是由多次获取输入和上下文、形成判断、执行动作共同组成的一条运行链。
就像传统 APM 采集指标、日志和 Trace,
并不是为了把数据堆得更多,
而是为了还原系统为什么慢、为什么错、为什么挂。
AI 可观测性也是一样。
日志记录的是事件。
可观测性还原的是现场。
所以,先把第一层说清楚:
AI 可观测性不能只停在模型监控。
只做模型监控,我们看到的是:
模型有没有被调用、响应快不快、Token 花了多少、回答有没有报错。
这些当然重要。
进入 Agent 监测以后,
我们开始看见它经过了哪些步骤、调用了哪些工具、哪里出现了异常。
接下来更难的问题是:
这次行为是在什么任务下,
获得了哪些输入和上下文,
依据什么做出判断,
又在怎样的业务规则、权限范围和审批要求下形成的。
所以 AI 可观测性真正要观测的,不只是模型输出。
而是一次 AI 行为,怎样在运行过程中形成。
看见调用链,还不等于解释了行为
上一篇提到,
一次本不该发生的动作被系统成功执行,
也可能变成生产事故。
事故发生以后,一条 Agent Trace 可能已经记录得很完整:
哪个账号发起了请求,
调用了哪个工具,
传入了什么参数,
接口什么时候返回,
动作是否执行成功。
这些数据能证明动作发生过。
但它们还不能回答:
AI 为什么认为应该执行这个动作?
它当时获得了哪些输入和上下文?
哪些关键事实没有被纳入?
为什么没有选择风险更低的方案?
这个动作为什么没有被审批或拦截?
所以,AI 可观测性不能只留下调用结果。
它还要把动作发生时的现场留下来。
那企业到底要留下什么?
我认为,至少要能回答四个问题:
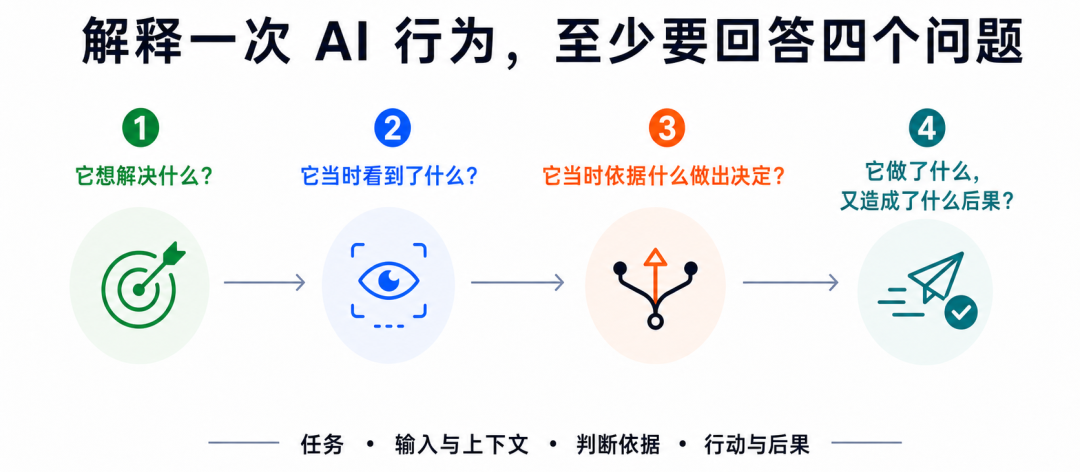
第一个问题:它想解决什么?
很多 AI 行为从一开始就埋下了偏差。
不是模型突然出错。
而是任务本身没有说清楚。
比如:
“处理测试环境问题”和“尽快恢复服务”,听起来都很正常。
但它们允许的行动范围完全不同。
前者应该被限制在测试环境。
后者则可能让 AI 主动寻找一切可用的恢复手段。
所以企业首先要回答:
AI 接到的任务是什么,
目标是谁给的,
任务边界是什么,
它是提供建议还是可以直接执行。
这里观测的不是一句 Prompt,而是 AI 当时到底想完成什么。
第二个问题:它当时看到了什么?
AI 不会凭空做出判断。
它会根据当时获得的输入和上下文,
形成一个“它所理解的现场”。
这些内容可能来自用户输入、历史上下文、知识库和业务数据、工具返回的结果,以及系统状态和运行环境。
真正需要看清楚的是:
它获得了哪些输入和上下文,
哪些内容已经过期,
哪些关键事实缺失了,
有没有内容被错误理解或者忽略。
这和简单保存一段 Prompt 不一样。
Prompt 只是入口。
企业真正需要还原的是:
AI 当时获得了哪些输入和上下文,又把哪些内容作为判断依据。
第三个问题:它当时依据什么做出决定?
知道 AI 看到了什么,还不够。
企业还要核对,它形成这个决定时依据了什么,又受到了哪些约束。
因为面对同样的输入和上下文,
AI 仍然可以选择查询、建议、请求人工确认,或者直接执行。
比如,
同样看到数据库连接数异常。
一个 Agent 可能先查询正在执行的会话。
另一个 Agent 可能直接清理连接,甚至重启实例。
看到的是同一个问题,
形成的动作却完全不同。
企业要继续还原:
它把哪些内容作为判断依据,
当时适用了哪些业务规则,
为什么排除了风险更低的方案,
当时的权限范围、安全策略和审批要求是什么。
这里观测的不是模型脑子里的每一句话。
而是能够被核对的判断依据和约束条件。
第 7 篇讲过行动边界。
到了可观测性这一层,
企业需要证明边界在当时有没有真正生效,
为什么这个动作被允许继续,
为什么本该发生的确认没有发生。
所谓“为什么”,
不是让模型事后讲一个故事,
而是用运行时证据还原这个判断是怎么形成的。
专业一点说,这里有三层能力:
Trace 负责串起执行路径,
Evaluation 用来判断行为质量。
要解释行为形成的条件,还要把 Trace、评估结果和其他运行时证据放在一起。
说白了,光知道它走过哪些步骤还不够,
还要知道这些步骤对不对,当时为什么会这么走。
只有这样,企业拿到的才不只是一条路径,
而是一份可以核对的现场记录。
第四个问题:
它做了什么,又造成了什么后果?
最后,企业不能只看 AI 执行了什么。
还要继续追问:
这个动作最终改变了什么,
它选择了哪个工具、操作了哪个对象、生成了什么参数,
改变了什么系统状态,
有没有触发后续流程,
有没有影响客户权益、交易结果或服务承诺,
出了问题能不能及时发现、停止和回滚。
后果也不只是有没有出事故。
任务有没有真正完成,
结果有没有被采用,
是否带来了返工,
这次投入到底值不值得,
同样需要被看见。
比如,
一个冻结账户的接口返回 200,
只能证明冻结动作执行成功。
企业还要知道:
冻结的是不是正确的账户,
冻结范围有没有被放大,
正常交易是否因此中断,
客户权益是否受到影响。
这里有一个很容易忽略的区别:
动作执行成功,不等于后果可以接受。
技术调用完成,只能证明动作发生了。
它不能证明对象选对了。
不能证明动作被允许。
也不能证明最终结果可以接受。
所以 AI 可观测性不能停在 Tool Call。
它还要把动作和真实后果连起来。
四个问题,缺一个都很难解释
把前面的内容收一下。
当企业需要解释一次异常行为、一次错误决策,
或者一次 AI 事故时,
至少要回答四个问题:
它想解决什么。
它当时看到了什么。
它当时依据什么做出决定。
它做了什么,又造成了什么后果。
任务。
输入和上下文。
判断依据、业务规则和权限边界。
动作与后果。
这四部分连起来,
企业看到的才不是一堆彼此分散的记录。
而是一次可以还原、可以解释、也可以复盘的 AI 行为。
专业一点说,
Evaluation 不应该只评估最终输出,
还要覆盖任务、输入与上下文、判断依据、动作和后果。
说得更直白一点:
评估不只是给答案打个分。
任务有没有问题,
判断依据是否可靠,
业务规则、权限或审批有没有被绕过去,
最后的动作企业能不能接受,
这些其实都要评估。
模型的自我解释,不能直接当证据

这里还有一个容易踩的坑。
事故发生以后,有人会重新问 AI:
你当时为什么这么做?
模型通常能给出一段听起来很完整的解释。
但这段解释,仍然是它此刻新生成的一次回答。
它可能合理。
也可能只是事后把事情讲圆了。
能说得通,不等于当时就是这么发生的。
所以 AI 可观测性不是让模型多写一段自我说明。
也不是保存一大段推理文字,就把它当作事故证据。
真正可以用于审计和复盘的,
是运行时留下的事实:
任务是什么;
它当时获得了哪些输入和上下文,这些内容来自哪里;
它把哪些内容作为判断依据;
适用了哪些业务规则、安全策略和审批要求;
当时使用了什么权限,权限校验和审批是否通过;
执行了什么动作;
最终改变了什么。
这些事实可以核对、可以验证,也可以追责。
这才是证据。
最后
传统可观测性观测的,是系统怎样运行。
AI 可观测性正在从模型监控走向 Agent 监测。
行业开始记录 Session、Trace、工具、检索、评估和风险事件。
说白了,就是尽可能把 Agent 当时做过什么留下来。
但把每一步记录下来,只是第一步。
企业还要用这些运行时证据回答:
任务是怎样被理解的,
当时获得了哪些输入和上下文,
判断依据是什么,
动作为什么被允许发生,
最终改变了什么,
又造成了什么后果。
只有把任务、输入与上下文、判断依据与边界、动作和后果连起来,
事故发生以后,企业才知道错从哪里开始,哪一道边界没有生效,下一次应该改哪里。
过去我们观测系统。
今天我们开始观测 Agent。
下一步,企业真正需要解释的是:
Agent 为什么这样做。
看见 Agent 做了什么,
只是 AI 可观测性的起点。
能用运行时证据解释它为什么这样做、最终造成了什么后果,
才是企业把 AI 放进生产系统后必须具备的能力。
行业参考:OpenTelemetry Generative AI semantic conventions、OpenAI Agents SDK tracing、Reasoning Models Don’t Always Say What They Think。
#AI系统 #AI运行系统 #AI可观测性 #因果AI #AgentOps
推荐阅读











