前段时间热播的电视剧《开端》想必不少人都看过的,其新颖的拍摄手法和不落俗套的剧情着实颇具亮点。

(图片来自sohu.com)
为什么要说到这部剧呢?因为这部剧可以更好的帮我们理解什么是系统的可观测性,让你从一大堆技术概念中解脱出来。
我们都知道,为了保障一个软件系统的正常运行,通常我们都会为它增加监控手段,这里边主要有两类监控:黑盒监控与白盒监控。
什么是黑盒监控与白盒监控?
黑盒监控是指对服务器的监控,重点关注磁盘空间、CPU 使用率、内存使用率、平均负载等领域,这些是业内大多数人认为要监控的标准系统指标。

(图片来自pandorafms.com)
白盒监控是对在服务器上运行的应用程序的监控,可能是从Web 服务器收到的 HTTP 请求数量到应用程序生成的响应代码时间等的任何内容。
只有监控是不够的
在剧情里,主角们发现异常后多次进行警告和报警,但是问题始终没有完美解决。因为这个系统很复杂,甚至于牵扯到之前的一个系统问题(作案嫌疑人之女的交通事故)。仅仅是针对当前状态的监控与告警,是无法让这个系统快速的从故障中恢复,更别说进行一次有效的迭代提升质量了。
所幸,剧情中的循环就类似我们的代码一样,它可以重来让我们充分的debug。一次次的重置就像一次次的上线一样,那么问题来了,无论是剧情里还是现实中循环终究是有限制的,所以我们需要尽快找到解决问题的办法。
剧情里的可观测性
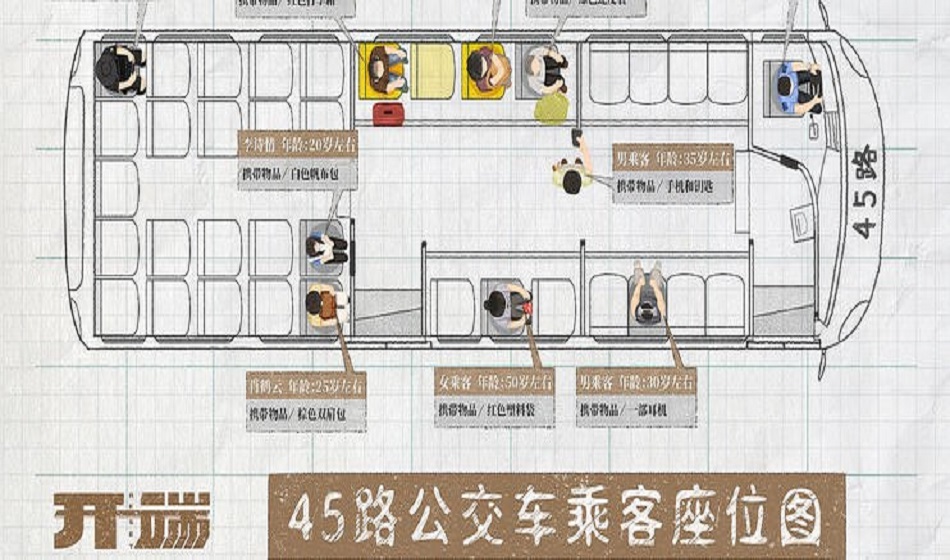
如果我们把公交车看成一个应用系统服务器,那个爆炸就是系统宕机的话,我们就会发现,这简直就是一部实现系统可观测性的好教材。
当男女主角身在公交车内时,对应的就是系统的白盒监控状态;当提前下车时,他们就和那些警察一样处于黑盒监控状态。
在两种状态相互交替下,他们会用心观查每个乘客的细节:每个人的位置、双肩包被紧紧抱住、行李箱非常扎眼、蛇皮袋被视若珍宝、高压锅用来装肉等等,这些是什么?聪明的你一定想到了,这些就是应用系统的部分指标数据(Metrics)。

(图片来自smzdm.com)
主角们记录的精确到几点几分的动作/行为,不仅忠实的还原了当时的情况,同时也为排查问题助了一臂之力,这不就是系统的日志数据(Logs)么。
随着剧情的推进,他们获取了更重要的数据,包括每个人物的关系,以及不同循环里事件的发展路径,这些也是对破案最为关键的信息,其实对应的就是系统的追踪数据(Traces)。
到此,构建可观测性的三大类数据支撑已经完备,我们也不难发现追踪数据(Traces)才是定位问题和解决问题的核心。
可观测性能定位根本问题
剧情最后,在主角们多轮艰苦卓绝的努力下,问题终于得到了圆满的解决。但是,我们该庆幸么?不,我们该反思。如果从一开始主角们就知道人物的关系和事件的先后顺序,破案还会这么困难么?答案自然是否定的。
回到我们的软件系统中,潜在复杂性的来源是永无止境的,监控可能变得异常复杂,以至于监控本身变得很脆弱、难以维护。因此,一套好的监控系统应该是简单并有效的,提供源自基于时间序列的设备、已知故障模式以及黑盒测试的关键业务和系统指标,而不是提供成百上千无太大意义的指标,意图“监控一切”的做法很多时候都是一种反面教材。

(图片来自dockone.io)
但可观测性则不同,它旨在提供对系统行为的高度精细的洞察以及丰富的上下文,非常适合指导调试并真正解决系统的问题。由于无法预测系统可能遇到的每一种故障模式,或预测系统可能出现异常的每一种可能方式,因此我们构建的可观测性是用证据而非推测进行调试系统,这很重要。






