
大家好,我是金全。
这篇里说的 AI,主要指已经接入工具、流程和业务系统,能够自己调用工具、推动流程的 Agent。
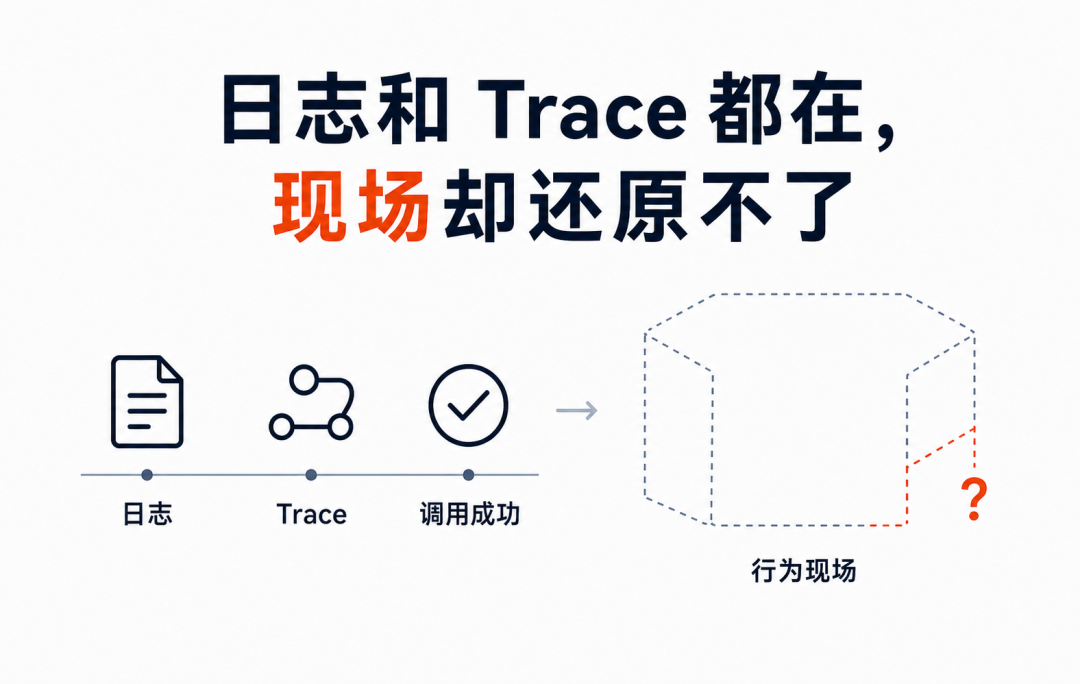
过去系统出事故,很多人的第一反应都是查日志。
看哪里报错了。
哪个接口超时了。
哪次发布引入了问题。
再进一步,就是看 Trace。
一次请求从哪里进来,经过哪些服务,
最后在哪里变慢、失败或者中断。
但 AI 事故麻烦的地方在于:
日志可能都在。
Trace 也很完整。
工具调用返回成功。
系统甚至没有出现一条报错。
可大家还是说不清:
Agent 当时为什么会这样做?
第 8 篇讲过一种新的事故:
调用成功了。
但这个动作不该发生。
第 9 篇继续讨论,
企业不能只看 Agent 做了什么,
还要把任务、当时看到的内容、判断依据、动作与后果连起来。
上一篇又讲到,
Agent 引用的资料可能都是真的,
却不适用于眼前这件事。
到了事故调查这一步,问题就变成了:
这些记录已经有了,企业该怎么用它们还原当时的现场?
日志和 Trace 都在,为什么还是说不清?
因为系统现场和行为现场,不是一回事。
系统日志擅长记录:
谁调用了接口。
传入了什么参数。
接口什么时候返回。
动作是否执行成功。
Trace 擅长把一次调用串起来。
它能告诉我们,请求经过了哪些系统,在哪个节点出现异常。
这些记录可以证明一件事发生过。
但 AI 事故往往还要回答另一组问题:
-
Agent 为什么认为这件事应该做?
-
它当时看到了什么,处在什么现场?
-
哪些重要情况没有进入它的视野?
-
为什么选择了这个动作,而不是先查询、先建议或者请求人工确认?
-
原本应该拦住它的规则和审批,为什么没有生效?
这些问题,不能靠把日志按时间排好自动得到答案。
因为:
日志记录的是事件。
Trace 还原的是调用路径。
AI 事故还要解释行为为什么一步步形成。
这也是 AI 事故和很多传统系统事故不一样的地方。
传统系统出错,我们首先会寻找故障点。
AI 出事故,技术系统可能没有故障。
真正出问题的,是一次行为形成的过程。
先看后果,不要先问模型
事故发生以后,最容易做的一件事,是先去问模型:
你当时为什么这么做?
第 9 篇已经讲过,这种事后解释不能直接当成事实。
模型可以把一件已经发生的事讲得很有道理。
但能说得通,不等于当时就是这么发生的。
所以调查 AI 事故,第一步不应该是让模型解释自己。
也不应该一上来就研究 Prompt。
应该先确认:
到底发生了什么。
比如一个客服 Agent 冻结了客户账户。
调查不能只停在“冻结接口调用成功”。
企业要先确认:
-
冻结了哪个账户。
-
影响了哪些交易。
-
持续了多长时间。
-
客户权益是否受损。
-
有没有触发后续流程。
-
影响是否还在扩大。
同样,一个运维 Agent 建议或触发了实例重启。
真正需要确认的也不只是重启命令有没有执行。
而是哪些服务因此中断,哪些任务被打断,业务有没有自动恢复,是否产生了数据不一致。
AI 事故调查,应该先从真实后果开始。
而不是先从模型回答开始。
因为只有先确定后果,企业才知道这次调查到底要解释什么。
沿着后果,一步一步往回追

系统设计通常是正向的:
任务。
现场。
判断。
动作。
后果。
但事故调查要倒过来。
后果。
动作。
判断。
当时看到的现场。
最初任务。
先看后果,是为了确定影响。
再看动作,是为了知道什么直接改变了系统或业务状态。
然后往回追:
-
Agent 为什么选择这个动作?
-
它把哪些内容当成了判断依据?
-
它当时看到了什么,哪些现场条件进入了判断?
-
最初接到的任务到底是什么?
举个例子。
假设一个运维 Agent 在重保期间建议或触发了生产实例重启。
系统记录显示:
重启接口返回成功。
权限检查通过。
实例也恢复了运行。
只看这些记录,好像没有问题。
但沿着后果往回追,可能会发现:
业务中断,是由这次重启直接造成的。
Agent 选择重启,是因为连续健康检查失败。
它引用的处置规范允许自动重启。
但这份规范只适用于普通业务时段。
当时正处于重保窗口,这个现场条件没有被带入判断。
而最初给它的任务是“尽快恢复服务”,
没有明确限制生产变更必须人工确认。
到这里,事故才真正被还原出来。
问题不在于运维 Agent 不能参与处置。
而在于企业必须能还原:
它为什么选择了这一步。
问题不是某一条日志缺失。
而是任务、现场条件、规则和动作之间,
没有被连成一条完整路径。
不只看它用了什么,还要看它没看到什么
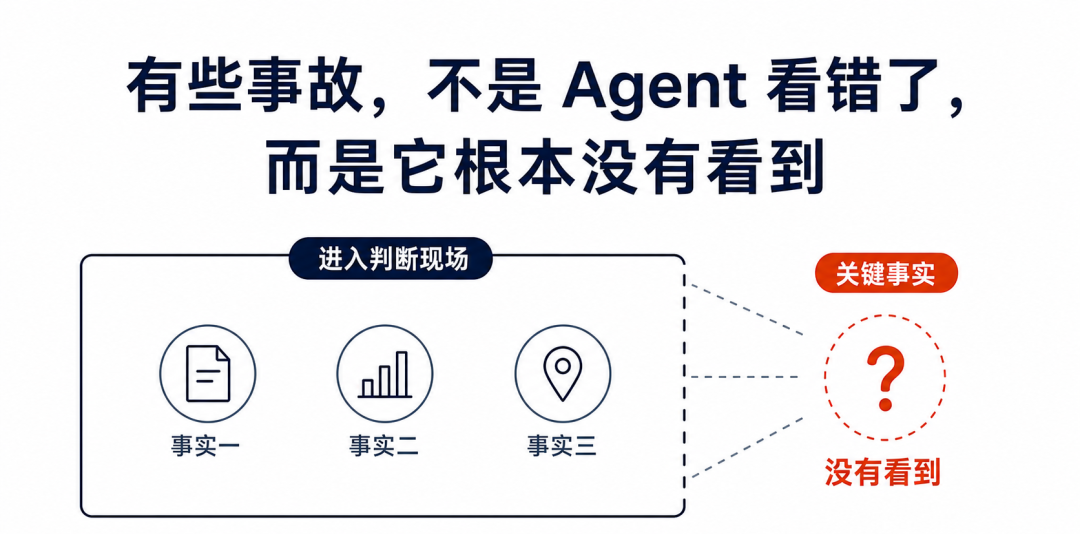
AI 事故调查还有一个容易忽略的地方。
很多人只检查 Agent 使用了哪些资料、调用了哪些工具、执行了哪些动作。
但真正改变调查结论的,往往是那些没有出现的东西。
有些事故,不是因为 Agent 看错了。
而是因为它根本没有看到。
它有没有漏掉一条最新制度?
有没有忽略当前正处于变更窗口?
有没有拿到客户的最新风险状态?
有没有看到刚刚撤回的审批?
有没有排除一条风险更低的处理方案?
有没有绕过本应发生的人工确认?
上一篇讲过:
资料是真的,不等于资料用对了。
到了事故调查里,还要再加一句:
看见 Agent 用了什么,不等于知道它遗漏了什么。
一次错误行为,有时不是因为 Agent 使用了错误信息。
而是因为关键事实根本没有进入它当时的判断现场。
所以,还原现场不能只拼接已经存在的记录。
还要检查:
哪些内容本来应该出现,却没有出现。
哪些规则本来应该生效,却没有生效。
哪些确认本来应该发生,却被跳过去了。
这一步,往往比找到一条明显报错更重要。
调查不能停在“模型错了”
很多 AI 问题最后会得到一个很省事的结论:
模型判断错误。
这句话可能没错。
但对企业几乎没有帮助。
因为它没有回答:
错从哪里开始。
为什么一路没有被发现。
哪一道边界没有生效。
影响为什么会继续扩大。
下一次到底应该改哪里。
一次真正有用的调查,至少应该说清楚四件事:
-
第一,最初偏差出在哪里。是任务没说清楚,现场条件不完整,资料不适用,还是规则使用错误。
-
第二,哪个动作把偏差变成了真实后果。
-
第三,原本应该拦截、确认或者降级的机制,为什么没有生效。
-
第四,下一次要改的是任务、资料、规则、权限,还是执行流程。
只有回答到这里,事故调查才不只是解释过去。
它才开始帮助企业避免下一次事故。
传统事故追故障,AI 事故还要追行为
我做了十几年 APM 和可观测性。
过去调查生产事故,很重要的一件事,
是用 Trace 沿着调用关系还原故障传播路径。
一条请求从哪里进入。
经过哪些服务。
在哪个节点变慢、报错或者中断。
这套能力仍然重要。
但 Agent 开始进入生产以后,企业还要多追一条路径:
一个任务怎样被理解。
哪些现场条件进入了判断。
为什么选择这个动作。
动作怎样改变了真实业务。
所以:
传统 Trace,追的是请求路径和故障传播路径。
AI 事故调查,还要追行为形成路径。
前者回答一次请求是怎么走的,
系统故障是怎样扩散的。
后者回答一次 Agent 行为是怎样一步步变成后果的。
这不是多保存几条模型日志就能解决的。
它要求企业把原本分散在模型、知识库、工具、权限、审批和业务系统里的记录,重新连回同一个现场。
最后
AI 出事故以后,
企业真正缺的往往不是一条日志,
也不是一条完整的 Trace。
而是一个能够被还原的行为现场。
这个现场里要有:
-
最初任务。
-
当时看到的内容和现场条件。
-
被采用的资料和规则。
-
没有进入视野的关键事实。
-
做出的选择。
-
通过的权限与审批。
-
执行的动作。
-
造成的真实后果。
把这些内容按时间排好,只能得到一份记录。
把它们之间的关系还原出来,
企业才可能知道事故为什么发生。
过去 Trace 帮我们把一次请求串起来。
未来 AI 可观测性,还要把一次 Agent 行为串起来。
还原现场,不是把日志和 Trace 按时间排好。
而是把后果一步步追到当时的任务、现场和边界。
这可能是 AI 进入生产以后,
事故调查首先要补上的一课。
#AI系统 #AI可观测性 #因果AI #AgentOps #AI运行系统






